


Testing the Big Five LLMs: Which AI Can Better Redesign My Landing Page?
We compare Gemini, o1 Pro, Grok3, DeepSeek R1, and Claude 3.7 at improving my current book webpage.

The best thing about AI is that it can code snippets I am not passionate about. I am glad that I no longer need to think as hard to write Javascript .reduce() or any Swift code.
With the new Flagship models coming in hot this month, like Gemini 2.5 and o1-pro, I thought it would be perfect to try those out in one category I suck most: visual design.

This is the perfect opportunity for me to replace the designer in me who is terrible with hand-eye coordination and always got bad grades in art classes because my teacher thought I was “not taking it seriously enough.” However, it is cheaper to benchmark LLMs than to go to therapy.
The Problem
I am writing a FOSS book about Engineering Management, and I have created a monstrosity of a home page below—as you can clearly see, I should get a designer.
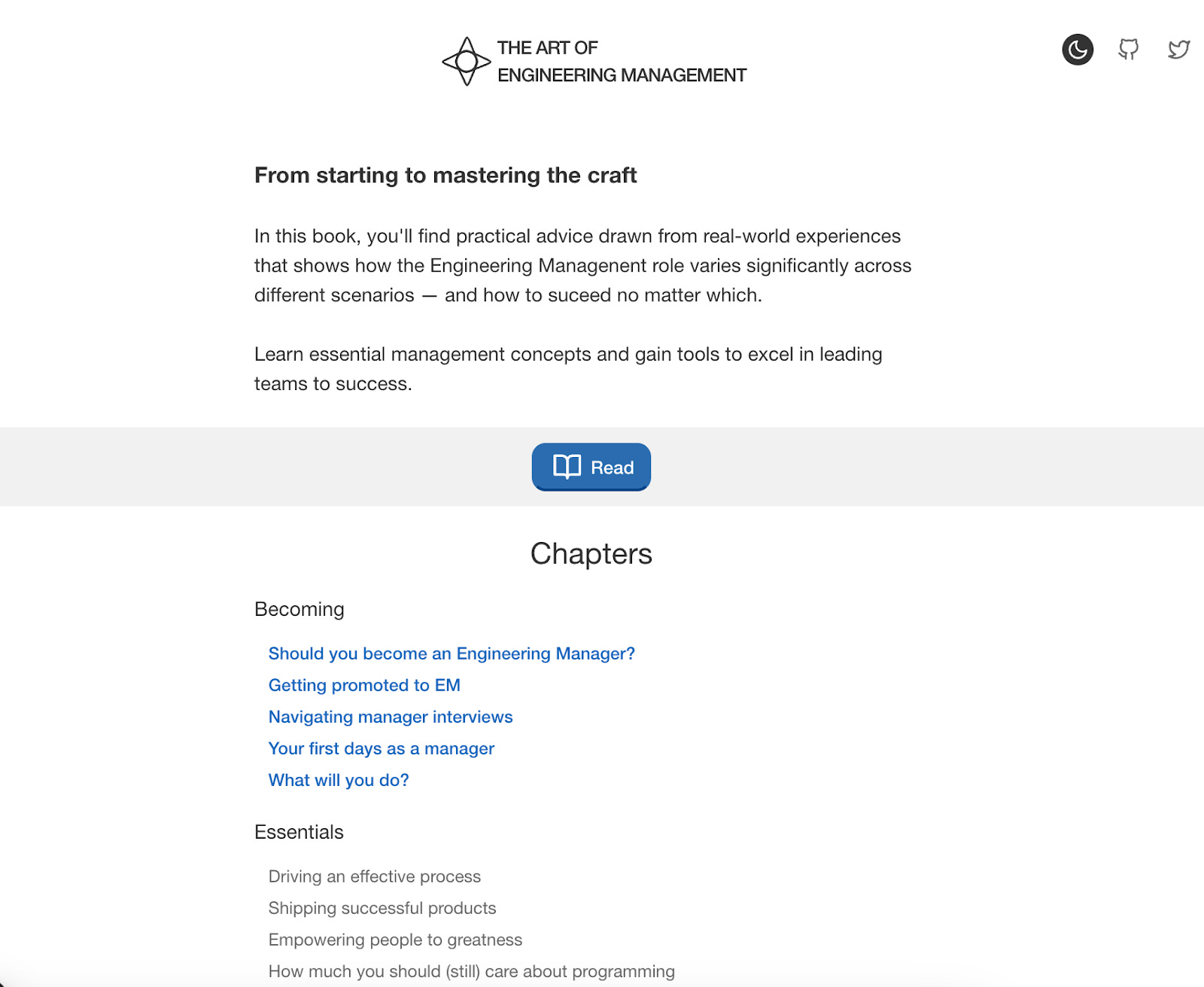
Job to be done
We will take a screenshot and the code of the current homepage and feed it to multiple flagship AI models to ask them to make it less horrible.
The most popular reasoning models currently are Google Gemini 2.5, OpenAI o1 Pro High, xAI Grok3 Think, DeepSeek R1, and Claude 3.7 Sonnet, so we are going with those.
System Prompt
I tweaked the system prompt in some preemptive benchmarks to improve common confusion points and things I missed.
I find this prompt good enough, even for non-reasoning models:
You are taking the role of a professional website designer. Your task is to restructure the home page of a book called “The Art of Engineering Management” to be more visually attractive.
For reference, the attached image shows the website's current rendering.
The website has a Header, an Intro with a call to action, and a table of contents. Below is a skeleton of the web page with JSX components and SCSS files. The SCSS file for the table of contents is empty.
You may use any popular JavaScript libraries such as Three.js, or custom illustrations by creating SVGs if you want to. However, you may not use any CSS frameworks like Tailwind.
Your objective is to return modified files that will improve the landing page's visual appeal and attractiveness. Return only the modified files without additional explanations. Nothing should be a "TODO." You will be judged by how well your design is after the original files are overwritten.One thing I am learning with system prompts is that if you ask LLM too much, they start failing catastrophically.
For example, it is okay to ask an LLM agent to create a unit test for a component, but if you ask: “create all missing units tests in my codebase,” it shits the bed terribly. So I am going to keep it simple.
Scorecard
Let's establish a system to evaluate the AI results. I have created a scorecard system to evaluate what we want the most:
Visual Design (50 points) - This is what we came for, so it should be half of the overall score
Interactivity (25 points) - Relates to mouse button hovers and scroll animations, basically “making it pop.”
Code quality (15 Points) - We should judge the code since having visual improvements is good and shouldn't come at the cost of code maintainability
Dark mode compatibility (10 points) - A “nice to have”: Our prompt doesn't even mention it so that we can focus on the above. If the AI messes this up, it is a quick fix.
Let's go!
I ran my current code against all the models and will share the code and the prompt when possible. Here is the original branch from which the code is used.
Deepseek R1
Let's start with the oldest one (I cannot believe I am calling an LLM released in January old). Deepseek produced a great concept with a few caveats.
The art doesn't mean much. The links with the underlines under them are fugly, and, most important, the shadows are terrible, and the hover effect of a shadow is dated.
But at least it works with dark mode!
The code is also not bad; it adds a lot of SCSS, but it is expected.
Result: Visual Design: 30 | Interactivity: 15 | Dark mode: 10 | Code Quality 10
Gemini 2.5
Google's new LLM has performed very well in many of my benchmarks. It makes the best even with the worst prompts.
This is very good. I have a few complaints about this design. I don't like the double columns of the chapters, but that is about it.
The hovering is great and presents the chapter in a very solid way!
In terms of code, it did surprisingly well, and it even fixed my bad dark mode logic, but on the other hand, it had a lot of unnecessary comments, which would not be ideal for pushing to the main as is.
Visual Design: 40 | Interactivity: 25 | Dark mode: 10 | Code Quality 10
Grok 3
Grok is the first one to disappoint me so far, but at least it made me feel better about my own design.
It repeated the book icon, “locked” the chapters as if I was selling a SaaS plan, and visually nested the cards too much.
Overall, there were some small changes, but none were positive.
It's also not stellar on the code side either, but at least I don't see any negative downsides.
Visual Design: 10 | Interactivity: 15 | Dark mode: 5 | Code Quality 10
o1 Pro High
o1 knows the key to my heart: I love blue and gradients. Maybe the fact that it did exactly how I liked it without me asking creeps me out.
I really like the header—it draws more attention than others. And instead of adding a generic SVG, it went with the best approach with the current LLM capabilities.
The chapter's menu is also not bad. I like that it starts over the banner, so it flows better.
The padding around the chapter's card could be better, and the broken white padding around the whole site might have been a mistake.
The dark mode is utterly broken.
On the code side, it is nothing bad; I could merge this as is.
Visual Design: 40 | Interactivity: 25 | Dark mode: 0 | Code Quality 15
Con… Oh wait, it's Claude Sonnet 3.7, with a steel chair!
I almost forgot Claude, to be honest. I always hear compliments on the code quality and how people prefer to use it on Cursor and Windsurf.
I am glad to see its greatness in UI design as well. That gradient is super sleek, and the subtle blue backdrop is also cool. The SVG, while not the most incredible one, was at least the most relevant.
I just didn't like that it added the famous “3 boxes with icons” that you see in every landing page template. Also, the bullet points and double columns are not visually pleasing.
Ironically, since Claude LLMs are praised for their code quality, I expected more; it tried to import a new font and tried to make the book's page flip, which clearly did not work.
Visual Design: 35 | Interactivity: 20 | Dark mode: 15 | Code Quality 5
Conclusion
The results are in:
Gemini 2.5: 40 + 25 + 10 + 10 = 85 points
o1 Pro High: 40 + 25 + 0 + 15 = 80 points
Claude 3.7 Sonnet: 35 + 20 + 15 + 5 = 75 points
Deepseek R1: 30 + 15 + 10 + 10 = 65 points
Grok 3: 10 + 15 + 5 + 10 = 40 points
One thing I missed in all the LLMs was improving the header text. I know that my callout is terrible because I am very bad at selling things. The system prompt even mentioned this, but all LLMs ignored it. But at least all the LLMs were successful in fixing 2 grammatical errors!
It is impressive that the AI “knows” how to better design a website without any visual aid to validate it afterward. Sure, it's not the Linear home page, and it won't win any Awwards, but in the end, I think that is the current LLM limitation. It is a blender of text absorbed by the corpus, resulting in an average of all designs worldwide.
I am also impressed by how the AI advanced. If I had tried this a few months ago, the results wouldn't be ready-to-run code. There would be just a few improvements in the code, but mostly not visual.
In the end, yes, any of those LLMs except for Grok would improve the current landing page, and I should have just applied the improvements instead of writing an article. However, I don't want an average book page. Even if I don't get paid for it, I want an excellent one.
So, for that reason, I am still getting a designer.